Animefaces 2M dataset
Developing a large-scale anime faces dataset.

Over the recent years, there have been multiple datasets in anime illustration generation space. The largest one is Danbooru dataset with ~5M images. Gwern (creator of the dataset) has put a lot of effort into cleaning and annotating the dataset. The original dataset only contains full illustrations, so he also created a subset of 512px portrait images focusing on faces. The only issue is that the dataset only contains 300K images and many images contain black padding around the image to ensure 512px size. Another good existing dataset is 90K images from safebooru dataset and Steven Evan’s Pixiv dataset both hosted on Kaggle. The dataset consists of top ranking pixiv images from 2018 ~ 2020. However, the faces dataset suffers from low resolution and the faces are too tightly cropped for my taste. To address these issues, I decided to create a large-scale animefaces dataset combining all three sources with a focus on maintaining high-quality. Below is a brief overview of how the dataset was created.
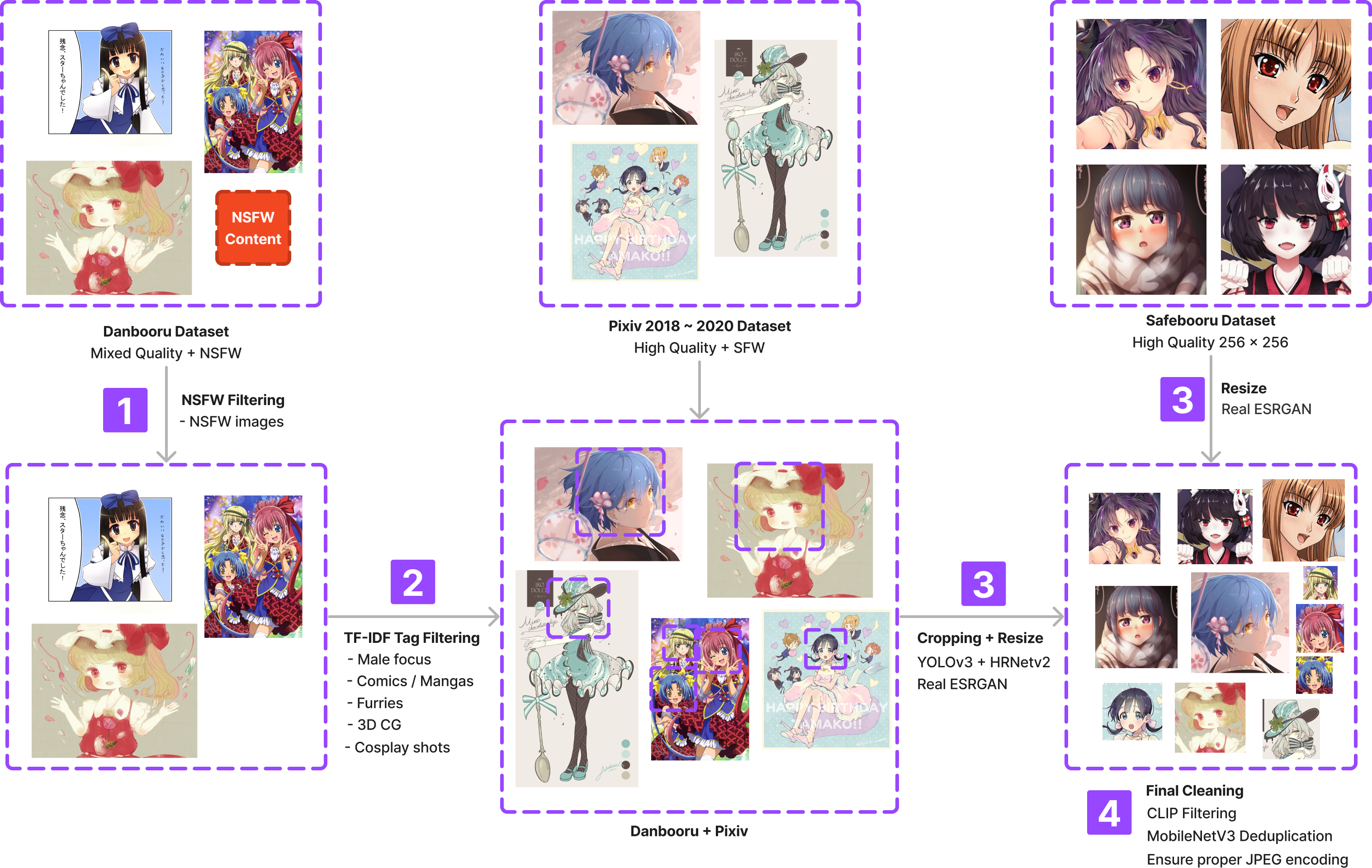
Data cleaning, filtering, processing, and all that jazz
Removing problematic images
The largest source of anime illustrations is Gwern’s danbooru dataset. Thanks to kind people in the internet, the dataset contains many NSFW images. Danbooru dataset has a tag system that allows us to filter out NSFW images. However, there are plenty of other undesirable images. To list a few:
- CG 3D images (tags: 3d)
- Manga / Comic (tags: comic)
- Furries (tags: furry)
- Cosplay images (tags: cosplay)
After manually identifying problematic images and their tags, I also wanted to find similar tags to the ones I identified. There are multiple approaches to find similar tags. One could simply extract GloVe/Word2Vec embeddings and find similar tags using cosine similarity. However, since the tags found in corpus are somewhat different to ones you might find in natural langauge, I’ve decided to resort to a more classical approach: TF-IDF.
The original TF-IDF algorithm is typically used to determine how relevant a word is to a document in a collection of documents. In my case, I use a modified version where I use it to find similar tags. Below is a short pseduocode for the algorithm:
# INPUTS
# TAGS:list[str] = list of all tags in the dataset
# POST_TAGS:list[list[str]] = list of tags for a given post
cooccurance = onp.zeros((len(TAGS), len(TAGS)))
# build cooccurance matrix
for tags in POST_TAGS:
for tag1 in tags:
for tag2 in tags:
cooccurance[TAGS.index(tag1), TAGS.index(tag2)] += 1
# compute TF-IDF
tf = cooccurance / cooccurance.sum(axis=1)
idf = onp.log(cooccurance.shape[0] / cooccurance.sum(axis=0))
tfidf = tf * idf
# query similar tags
tag = "furry"
similar_tags = TAGS[onp.argsort(tfidf[TAGS.index(tag)])[::-1]]
print(similar_tags)For readers who are not familiar with TF-IDF, the key intuition behind TF-IDF come in two parts. Firstly, if two tags co-occur frequently, they are likely to be similar. Secondly, if a tag appears in many posts, it is likely to be less relevant. For instance, the tags “comic” and “4-koma” are likely to co-occur frequently. However, the tag “comic” and “solo” are also likely to co-occur frequently becuase “solo” is a very common tag. Therefore, we need to weigh the co-occurance by the inverse of the number of posts that contain the tag. This is exactly what TF-IDF does. It’s easy to see that the above algorithm runs in time, where is the number of tags. For that reason, I decided to only use top 1024 frequent tags.
Filtering out the obvious
Even after removing NSFW images and other problematic images, there are still many images that are not suitable for training.
- Images that are too small
< 10KB - Images that are too large
> 100MB - Files that are not images (i.e.
gifandmp4files) - Images are in both
.jpgand.pngformat
The steps for filtering and processing these images were somewhat obvious. In fact, I have to credit Gwern here again for his detailed blog post.
- Filter out any images that are not in jpg/png format using
grep - Delete empty images using
find - Filter out images whose file size is less than 40KB using
find - Resize images to have max dimension of 1024px using
mogrify
Face detection
The next step is to detect faces in the images. For the longest time, nagadomi’s anime face detector has been a standard tool for anime face detection. For the most part, the detector works well on most cases and runs quite fast. But, I’ve noticed that the detector fails to detect faces in some images. For that reason, I’ve decided to use hysts’s YOLOv3 anime face detector which not only yields better results but also provides facial landmarks. In this step, it’s wise to filter out images containing multiple faces using “solo” tag, but I was confident enough about the face detector that I skipped this step. After filtering out the faces, I disregard faces whose resolution is less than 64px. In rare cases where the face is larger than 512px, I rescale it down to 512px as well.
Upscaling and resizing
The final step is to upscaling all the images to 512px resolution. The questino is how? The standard approach in this domain is to use waifu2x which is a CNN-based upscaler. A more recent approach is to use ESRGAN which is a GAN-based upscaler. The ESRGAN model also has a 4x upscaler which is trained on anime dataset. I happened to have a decent access to K80 GPUs, so I decided to use ESRGAN for upscaling. Using these methods, I end up with 512x512 high resolution face images. A similar approach is used for both safebooru and pixiv datasets.
Deduplication and CLIP filtering
The final step is to remove duplicate images and last round of quality checks. Since Danbooru dataset is quite large, it’s likely that there are many duplicate images between and within the datasets. For deduplication, I use imagededup library and use a MobileV3 embeddings to perform the deduplication across the images. This part is the most time consuming process. If anyone wants to perform deduplication on a larger dataset, I would advise using a ligther method such as PHash. After deduplication, I use CLIP to further filter out images that are not faces.
CLIP is a model proposed by OpenAI which is been trained on billions of images and text pairs. The model has been widely used for many applications and quite useful for filtering content based on text prompts. Even after thorough filtering, I still found a couple of images which had undesirable content in style, format, and color. To filter out these cases, I use the following prompts:
Manga / Comic
- “a comic strip”
- “an illustration”
Color
- “a monochrome image”
- “an anime girl drawn in color”
Style
- “a girl drawn in realistic style”,
- “a photorealistic image”,
- “an anime girl drawn in rough sketch style”,
- “an anime girl drawn in common style”
After manually playing around with a few thresholds, I find that around CLIP score of 0.7 ~ 0.8 works well for filtering out undesirable images.
Models, training, and results
Now, what are the models you can train with this dataset? The dataset can be an execellent benchmark for unconditional image generation. I am planning on releasing a larger dataset with various conditioning information such as tags, text, and sketches. But, for now, I have focused on unconditional image generation. Most of the models are implemented in JAX and Equinox for GPU/TPU training. I also maintain a pytorch version of the codebase which leverages flash attention and accelerate library. I plan to open-source the code in the near future.
ViT-VQGAN

ViT-VQGAN is a model which is commonly used to quantize high resolution images into a discrete latent space. This allows us to train image generation models efficiently without losing much quality. Below are non-cherry-picked samples from both 256px and 512px models.

The top/left images are the original images. The bottom/right images are the reconstructed images from the quantized latents. One can observe that higher the compression rate causes a significant loss in quality. For instance, compare 16x16 compression against 32x32. 16x16 compression mostly captures the overall structure of the image but loses finer details in comparison to 32x32 compression.
MUSE
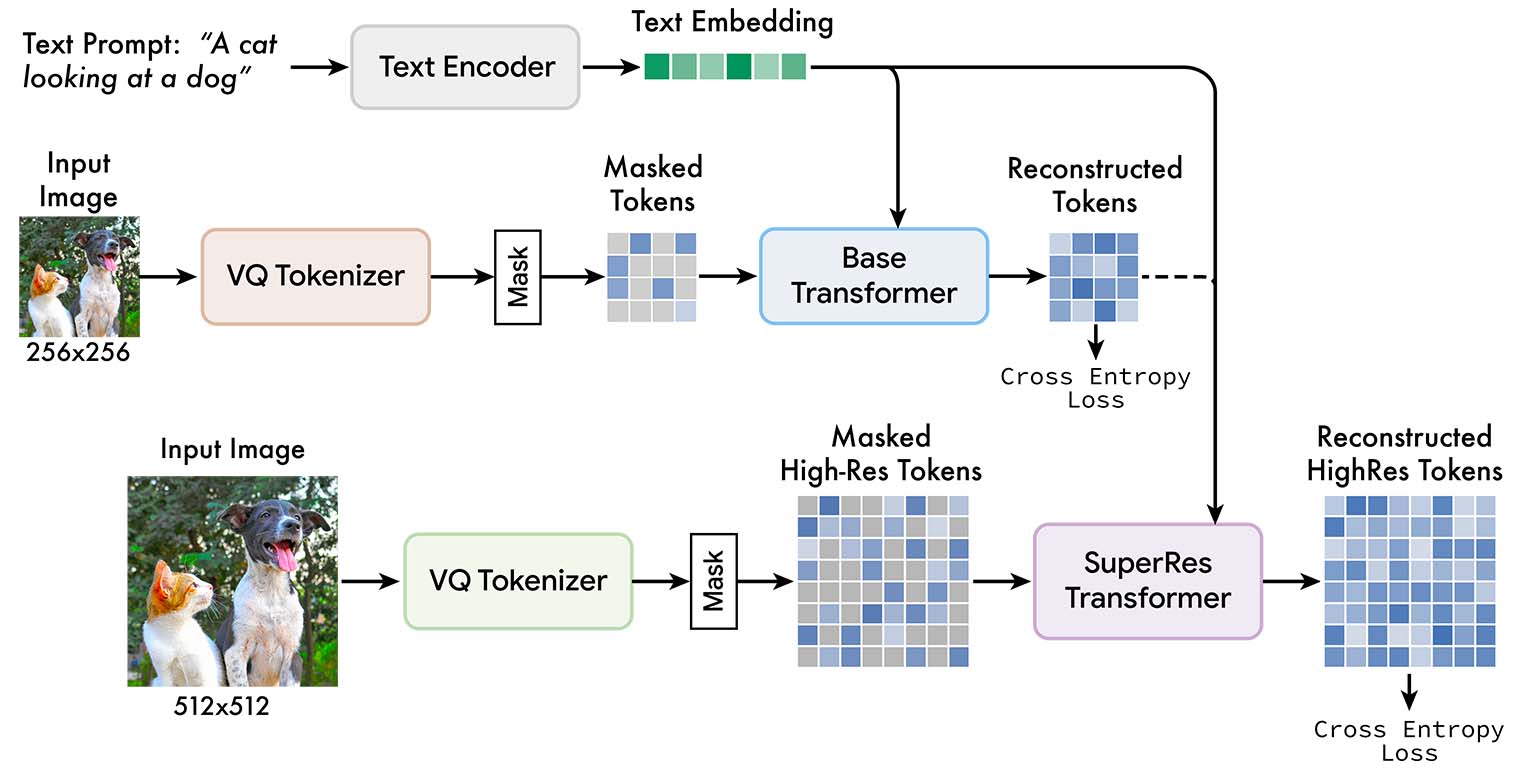
Using these quantized latents, one can train a transformer model to iteratively “demask” tokens to generate images. This is the approach taken by MASKGIT, MUSE, Paella, and MAGE. Above figure (taken from MUSE paper) provides a schematic overview of the model.

By leverging ViT-VQGAN 16x16 models, I was able to train a relatively small (around 100M ~ 300M parameter) 1st stage MUSE model at 256px resolution on TPUv3-8 hardware. The generation results are certainly not Stable Diffusion level, but I was glad to see that I was able to reproduce the results from the paper. I plan to scale up the experiments using much larger models.
Stylegan

Despite the popularity of Diffusion models, I’ve been a long supporter of GANs. It still has a lot of benefits over diffusion models such as faster sampling, lightning speed training time, and controllable latent space. Above are trained models from custom Stylegan implementation that I wrote a couple of years ago. I may try to reproduce results from GigaGAN paper to explore this direction. Here are a few more cherry picked samples from the model.

Diffusion models

For diffusion models, I’ve implemented methods from EDM paper to generate images on 64x64 resolution. As a devoted member of transformers cult, I’ve used a ViT backbone for training the diffusion model. Above are a few samples from the model. Certinaly, the quality is not as good as I want it to be. I plan to revise the implementation to improve the sampling quality.
Next steps
The obvious next step is to extend the dataset to full illustrations. To the best of my knowledge many teams and companies (NovelAI / Waifu Diffusion) use Danbooru dataset for training diffusion models. I wanted to provide a dataset to the open-source and research community which makes image generation on anime dataset even more accessible. I’ve gotten decent results using the current dataset, but I want to extend the data to incoporate full illustrations. I’ve already done basic cleaning/filtering/processing for the full illustrations, but I need to perform deduplication and CLIP filtering. I plan to release this dataset in the near future. But, here are a few ideas that I have in mind for the full illustration dataset.
- Extract image text embeddings from CLIP/LLM/SSL models
- Ensure high quality images using Pixiv dataset as anchor
- Figure out cropping and padding strategy
- Translate Danbooru tags into natural text (OpenAI API)
- Extract lines, depthmap, skeletons for ControlNet like training
Closing words
Again, I would like to thank Gwern, hysts, and nagadomi for their amazing work and contributions to the community. I would also like to thank Activeloop team for giving me the oppurtunity to share my work. Moreover, I want to thank Google’s Tensor Research Compute (TRC) program for providing compute resources for this project. I hope this dataset will be useful for future anime generation research.